Ninety Six Spreadsheets
Here’s another application for Python and Excel: opening a folder of spreadsheets and pulling specific data from each spreadsheet.
As a part-time bookkeeper for my wife’s restaurant, I needed to review the history of raises for a couple of her employees. Unfortunately, the actual pay rate was spread across 96 different spreadsheets representing almost four years of pay history. A typical payroll sheet looks like this:
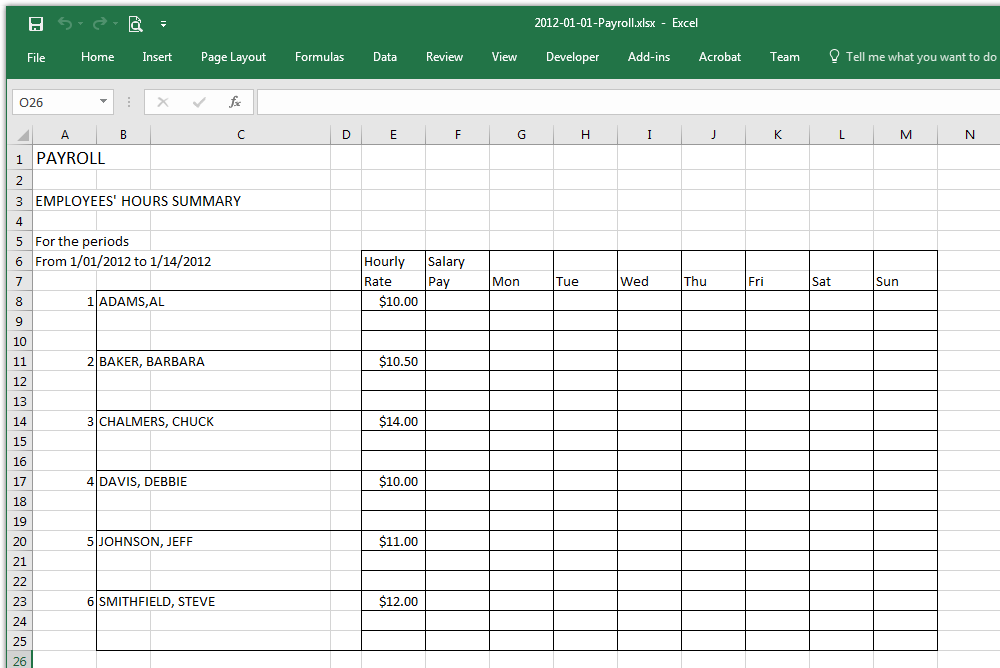
To manually click through each spreadsheet, locate the pay rate for Steve and Jeff, write it down, and go to the next spreadsheet would take about 30 seconds per spreadsheet. Instead of spending almost 50 minutes opening and closing spreadsheets, I decided to invest 10 minutes in a Python script I could use over and over.
The script opens every .xlsx file in the local directory and extracts the list of employee names from column B. If either Steve or Jeff is found in the list, their salary is recorded. After all the spreadsheets are read, the script prints out the results. The spreadsheets are named “2012-01-01-Payroll.xlsx” for January 1, 2012, “2012-01-15-Payroll.xlsx” for January 15, 2012, and so on.
The brief example on Github contains two spreadsheets: 2012-01-01-Payroll.xlsx and 2012-01-15-Payroll.xlsx. The script opens these files, extracts payrates for Jeff and Steve, and writes the payrates to jeffsteve.csv as shown below:
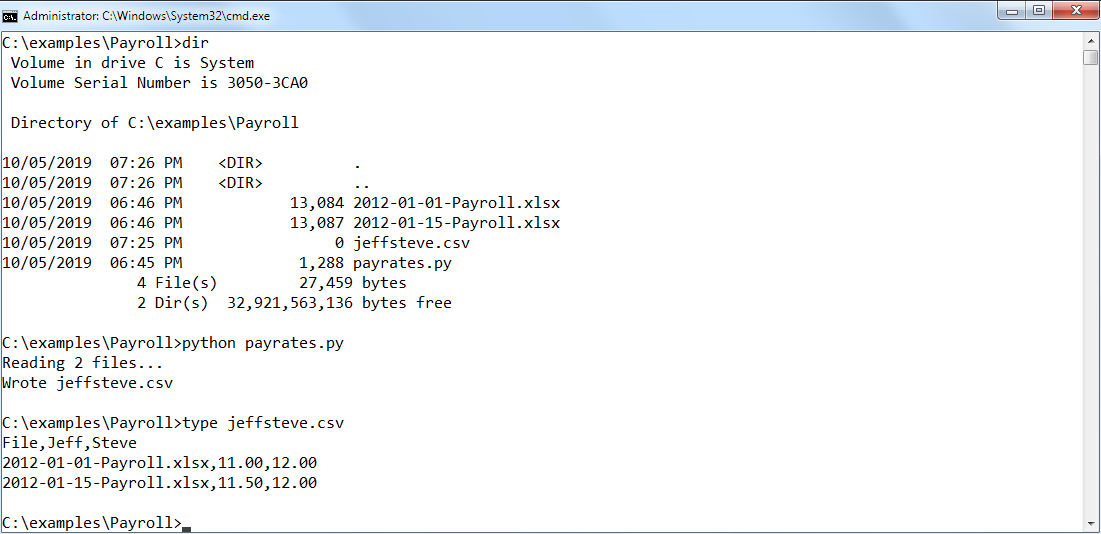
The completed script is available at https://github.com/pythonexcels/examples/blob/master/payrates.py. The sample spreadsheets are available at https://github.com/pythonexcels/examples/raw/master/Payroll/2012-01-01-Payroll.xlsx and https://github.com/pythonexcels/examples/raw/master/Payroll/2012-01-15-Payroll.xlsx if you’d like to test the script yourself.
#
# payrates.py
# Report payrates for two employees across multiple spreadsheets
#
import win32com.client as win32
import glob
import os
xlxsfiles = sorted(glob.glob("*.xlsx"))
print ("Reading %d files..."%len(xlxsfiles))
steve = []
jeff = []
cwd = os.getcwd()
excel = win32.gencache.EnsureDispatch('Excel.Application')
fpjeffsteve = open('jeffsteve.csv', 'w')
for xlsxfile in xlxsfiles:
wb = excel.Workbooks.Open(cwd+"\\"+xlsxfile)
try:
ws = wb.Sheets('PAYROLL')
except:
print ("No sheet named 'PAYROLL' in %s, skipping"%xlsxfile)
jeff.append(0.0)
steve.append(0.0)
wb.Close()
continue
xldata = ws.UsedRange.Value
names = [r[1] for r in xldata]
if u'SMITHFIELD, STEVE' in names:
indx = names.index(u'SMITHFIELD, STEVE')
steve.append(xldata[indx][4])
else:
steve.append(0)
if u'JOHNSON, JEFF' in names:
indx = names.index(u'JOHNSON, JEFF')
jeff.append(xldata[indx][4])
else:
jeff.append(0)
wb.Close()
fpjeffsteve.write ("File,Jeff,Steve\n")
for i in range(len(xlxsfiles)):
fpjeffsteve.write ("%s,%0.2f,%0.2f\n"%(xlxsfiles[i], jeff[i], steve[i]))
print ("Wrote jeffsteve.csv")
excel.Application.Quit()
Originally Posted on September 22, 2012 / Updated November 1, 2022